












幻の犬問題
堀口大學/山田耕筰の『幻の門』といえば、三田の慶應ですが、こちらは『幻の犬』。
検索というのは、基本的にパターンマッチングシステムのことを意味します。
与えた入力にマッチする検索対象が返ってくるのが理想ですが、どう入力するのか、何と比較するのか、どう出力させるかには様々なバリエーションがあるため、一筋縄ではいきません。
インターネットが立ち上がって以降、有力なのは「文字を入力して言葉に突合させ、その文章に付随したモノを出力する」パターンです。“そんなのカンタンだろう”と思ったあなた。実はそんなに簡単ではありません。そんなに簡単で単純ではないからこそ、goo search solutionをはじめサイト内検索を重要視したサービスが必要とされているのです。
そもそも、「言葉」は「文字の連なり」として表現されます。検索対象となる文章も、同様に文字の連なりで表現されています。となると、検索とは基本的にある文字のカタマリが含まれるかどうかを調べる、という処理に帰着することができる……はずです。
さて、ある「文字」を表すには様々なやり方があります。まず文字を表すための文字コードにしても、いわゆるJISコード、unicode、戸籍統一文字番号、住基ネット統一文字コード、入管正字コードなど、様々なバリエーションがあり、今後もおそらく増えていきます。
コンピュータが処理できるのはビットのカタマリのみであり、直接言葉や文字を処理することはできません。そこで言葉を文字のカタマリとみて、それぞれの「文字」を文字コードという番号に変換し、この番号を一定のエンコーディング(変換方法)によりビットのカタマリに変換して処理します。検索語と検索対象が同じ文字コード体系・同じエンコーディングになっていれば、同じ文字の連なりは同じビットのカタマリになって、見つかるはず……と思われるかもしれません。しかし、ここに『幻の犬』問題が潜んでいるのです。
エンコーディングの一種にEUC-JPというものがあります。これは、番号体系としてJIS X 0208などのいわゆる「JISコード」を用い、JISコードの区・点それぞれの値に0xa0=160を足して順に並べたデータで文字を表します(厳密にはこの他に面も絡んでくるのですが、ここでは省略)。
例えば、『犬』という文字は「JISコード」で(1面)24区4点なので、160を足した184,164(=0xb8,0xa4)という値の並びになります。同様に『幻』は(1面)24区・24点なので184,184(=0xb8,0xb8)、『の』は(1面)4区46点なので164,206(=0xa4,0xce)となります。もうお分かりですね。『幻の』という文字の並びは、184,184,164,206というデータの並びになります。この二番目と三番目、184,164という値の並びは、『犬』に対応する値の並びである184,164と全く同じです。すなわち、「JISコード」の文字データだけを単純に追うと『幻の』という文字列が『犬』という検索語にマッチしてしまうのです!

どうしてこういった問題が起こるかというと、「文字」の境界を意識せず、単なるビットの並びとして処理してしまったからでした。文字の区切りを意識することができれば、(184,184),(164,206)という並びは(184,164)という並びにマッチしなくなります。
つまり、言葉を処理するためには言語の問題を避けて通ることができず、その影響は隅々にまで波及するのです。だがしかし、これで話は終わりません。仮にその文字列が含まれていたとしても、それが狙った結果なのかどうかについて注意する必要があります。
例えば中国の都市の事を調べたくて「北京」で検索した場合、京都の北部である「北京都」の情報は出力されるべきでしょうか? あるいはパソコンのことを調べたくて「バイオ」と入力した場合、生物工学関係の「バイオ」やゾンビゲームの「バイオハザード」、人生浮き沈みの「バイオリズム」、色の「バイオレット」なども一緒に出力されるべきでしょうか?
恐らくそうではないでしょう。これは、検索語として入力した文字列が何を示しているかを認識し、区別しなければ、広範な対象をうまく扱えないことを意味します。
すなわち単語としての扱いだけでは不十分で、それが何を意図して入力されたのかを推定し、異なるカテゴリにある言葉をひくなり、優先度を落とすなりといった処理を行う必要があります。
「東京」で検索して、千葉県袖ヶ浦の「東京ドイツ村」が出てくるべきなのかどうか、あるいは千葉県成田市の「新東京国際空港」を出して良いものなのかどうなのか、では浦安市の海沿いある夢の国はどうなのか。埼玉県川越市にある東京国際大学はどうなのか。大変難しい判断を迫られます。
それでもマッチしてれば良いほうですが、マッチしない方に大事な情報が入っていることもありますので、その対策も必要になってきます。パソコンのバイオであれば、「vaio」で入力したほうが対象とする文脈を限定できるため、より有用な結果に結びつくと期待できそうです。
しかしながら、説明文として「バイオ」というカタカナ表記しかなかったり、「VAIO」という大文字表記しかなかったりといったデータには、今まで述べてきたような、単純なやり方ではヒットすることができません。英語のアルファベットで大文字小文字の問題に限れば単純な話ですが、全角・半角なども絡んでくると、単純なやり方では変換することができません。
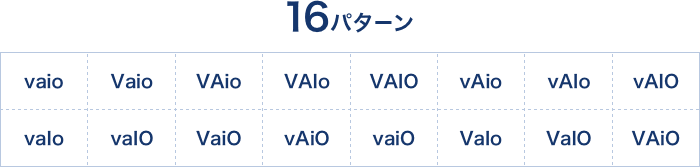
これらにマッチするためには、全く異なるビットの並びである「vaio」と「バイオ」が同じものを指している、という知識を持ち、しかもこれらを同一視してマッチするという機能を持っていなければなりません。大文字小文字のバリエーションを考えると、「vaio」は全部で16通りの表現型があります。文字数が増えていくに従ってこの表現型は指数的に増加するため、一般的にこれらすべての対応表をあらかじめ持っておくことは不可能に近いはずです。
それでも、パソコンにとって、異なるビットの並びを同じ言葉のバリエーションとみなす情報を充分に持っていないと、ユーザーが検索したかった情報にヒットすることができません。なにしろユーザーはすべての検索対象を知っているわけではないので、「vaio」はヒットするけど「バイオ」はヒットしないといった、本当の「正解」を知りません。「vaio」で検索してみたらヒットしたのに、「バイオ」で検索してクロレラしか出てこなかったばっかりに、がっくりと肩を落として、別のサイトに行ってしまう事態は回避しなければなりません。
検索のファースト・トライでいかにユーザーの期待を裏切らないか、ユーザーが望んでいるであろう検索結果をちゃんと出すことができるのかどうか、が最大のポイントになってきます。
そのためには、単なる部分ビット列の同一性探索を越えた、パターンマッチングアルゴリズムが大変重要になってきて、それこそがgoo search solutionsの存在意義となっているのです。
お気軽にお問合せください
ご要望に合わせたご提案をさせていただきます。
サービスのご説明をご要望の場合もお問い合わせください。
オンラインミーティングにて対応させていただきます。